我们擅长商业策略与用户体验的完美结合。
欢迎浏览我们的案例。
IT之家 3 月 2 日消息,阿里通义实验室语音团队今日发布了两款支持 FreeStyle 指令生成的模型 Fun-CosyVoice3.5 与 Fun-AudioGen-VD。
官方宣称,无论是精细控制声音表达,还是从零设计音色与场景,都可以通过自然语言指令直接生成。两款模型均支持通过自然语言指令控制语音生成,但应用方向不同:
Fun-CosyVoice3.5:多语种复刻 + 精细化表达控制
Fun-AudioGen-VD:声音设计 + 场景化音频生成
Fun-CosyVoice3.5
该模型支持 FreeStyle 指令控制,CosyVoice3.5 在 Instruct-TTS 方向实现能力升级,支持 FreeStyle 指令控制生成效果,一句话自由生成语音。
用户可以直接用自然语言描述表达方式,例如:“语气坚定一点”、“稍微压低音调,语速慢一点”、“带一点情绪起伏”...... 模型即可理解并生成相应表达。
Fun-CosyVoice3.5 新增支持泰语、印尼语、葡萄牙语、越南语。同时在 13 种语言的 WER 和 SpkSim 客观指标上保持“业内领先”。
针对生僻字、复杂语句等容易读错的场景专项优化,Fun-CosyVoice3.5 生僻字读错率从 15.2% 降至 5.3%,复杂文本表现更加稳定,长文本朗读也更稳定流畅。
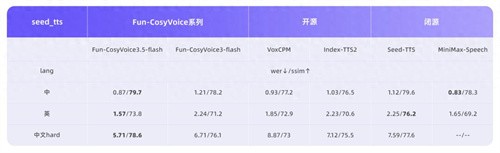
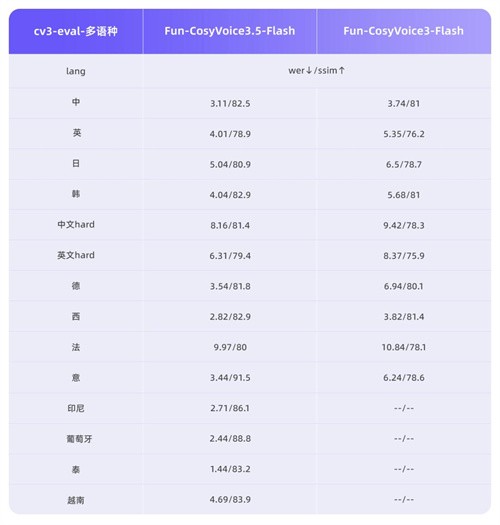
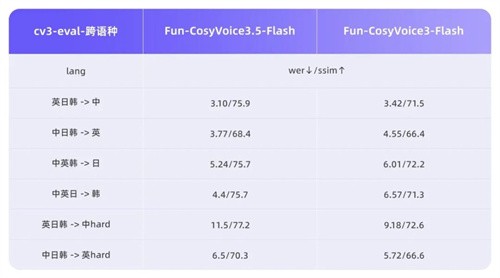
此外,Fun-CosyVoice3.5 通过强化学习技术专项调优,双重提升听感,使整体听感更加自然,表达更有层次。性能方面,Fun-CosyVoice3.5 的 Tokenizer 帧率减半,首包延迟降低 35%,在实时交互场景下响应更快,体验更流畅。
Fun-AudioGen-VD
Fun-AudioGen-VD 支持根据自然语言描述,生成目标音色、情绪表达和完整听觉场景,实现“人物 + 场景”的一体化声音生成。
基础属性:性别、年龄、口音、音高、语速
音质特征:沙哑、清亮、低沉、磁性......
情绪表达:愤怒、悲伤、兴奋、坚定......
角色模拟:客服、老兵、孩童、AI、播音员......
复杂心理:支持细腻状态表达(如“表面镇定但内心颤抖”)
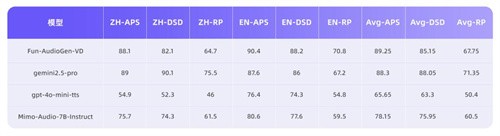
Fun-AudioGen-VD 不仅能生成声音,还能生成声音所处的“世界”,打造沉浸式听觉场景。
背景环境音:叠加城市喧嚣、咖啡馆背景、战场轰鸣等环境音;
空间混响效果:模拟大教堂、金属牢房、水下等空间回声;
设备听感滤镜:还原老式广播、对讲机、呼吸面罩等特殊音质;
动态环境互动:支持风噪断续、回声变化、嘶哑效果等实时互动。