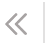我们擅长商业策略与用户体验的完美结合。
欢迎浏览我们的案例。
Meta 最新推出的视频跟踪工具CoTracker,发布没多久就在 GitHub 上斩获了 1.4k 星标。
从官方发布的几个 DEMO 来看,效果还是很震撼的。
对这个新“玩具”,有网友评论说,它不仅能改变物体追踪技术,也将在体育(动作)分析、野生动物追踪,甚至电影后期领域掀起一场新的革命。
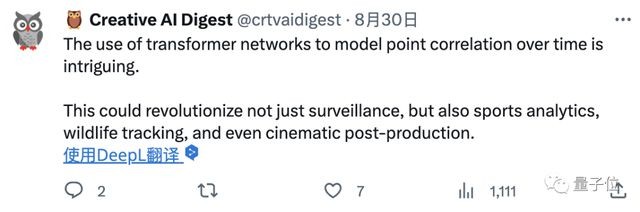
不过,在线 DEMO 是个简易版本,还不支持自定义跟踪位置,只能根据输入的跟踪数量等距分配。
但是如果自己部署、用代码操纵的话,就可以设置任意跟踪点了。
说到这我们正好来看一下 CoTracker 该怎么部署。
首先是 Colab 版本,我们刚刚说到的自定义跟踪点也在 Colab 当中。
Colab 的过程不必过多介绍,进入之后运行笔记中的代码就可以了。
而如果想自己动手的话,最简单的方式是从 torch.hub 中直接调用已完成预训练的版本。
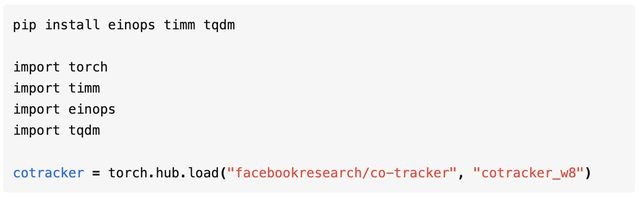
如果要对模型进行评估或训练,那么使用 GitHub Repo 更为合适。
首先要安装一下程序和相关依赖:

然后下载模型:
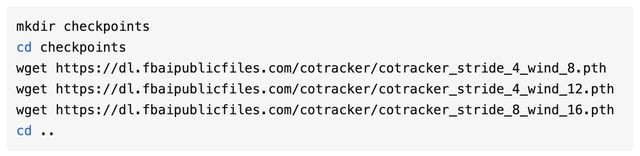
有关评估和训练的方式,可以到 GitHub 项目页来查看,链接放在了文末。
那么,CoTracker 又是怎么实现像素级追踪的呢?
评分超过 DINOv2
虽然都是追踪,但 CoTracker 和物体追踪模型有很大区别。
CoTracker 并没有基于语义理解对视频中物体进行分割的过程,而是把重点放在了像素点上。
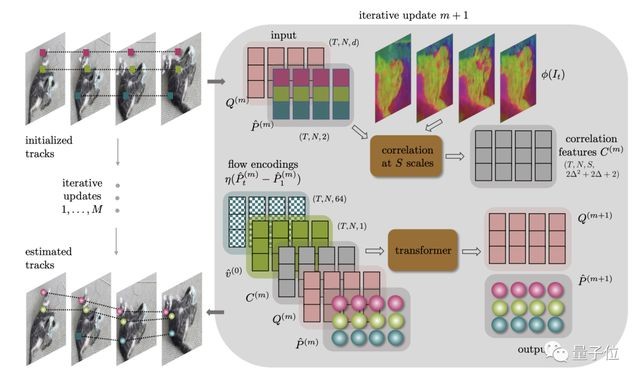
底层方面,CoTracker 采用了 Transformer 架构。
Transformer 编码了视频中点的跟踪信息,并迭代更新点的位置。
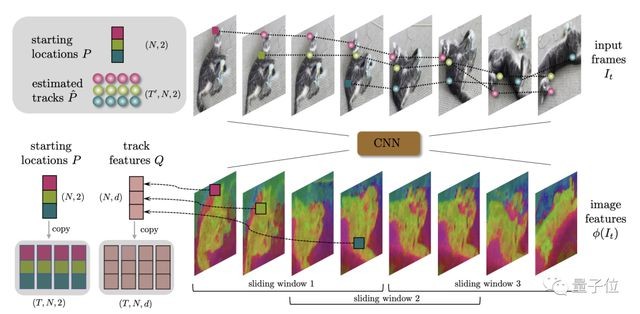
推理上,CoTracker 还采用了一种窗口机制,在时间轴上划分出滑动窗口。
CoTracker 使用上个窗口的输出对后面的窗口进行初始化,并在每个窗口上运行多次 Transformer 迭代。
这样就使得 CoTracker 能够对更长的视频进行像素级跟踪。
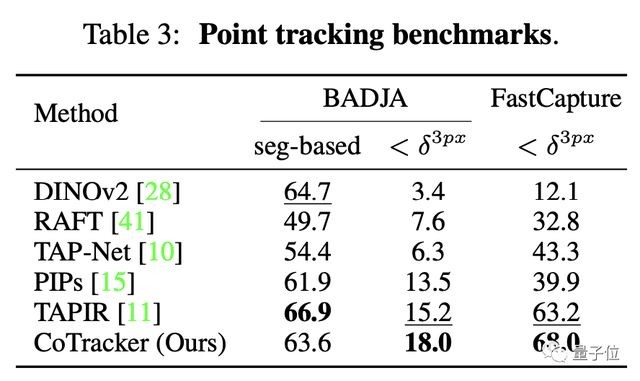
总之,经过一番训练之后,CoTracker 取得了一份不俗的成绩单。
在 FastCapture 数据集测试上,CoTracker 的成绩在一众模型中脱颖而出,其中也包括 Meta 自家的 DINOv2。
总之,喜欢的话,就赶紧体验一下试试吧!