我们擅长商业策略与用户体验的完美结合。
欢迎浏览我们的案例。
周四,英国的明星 AI 芯片公司 Graphcore 发布了一款 IPU 产品 Bow,采用台积电 3D 封装技术,性能提升 40% ,首次突破 7 纳米工艺极限。
全球首颗 3D 封装芯片诞生!
周四,总部位于英国的 AI 芯片公司 Graphcore 发布了一款 IPU 产品 Bow,采用的是台积电 7 纳米的 3D 封装技术。
据介绍,这款处理器将计算机训练神经网络的速度提升 40%,同时能耗比提升了 16%。
600 亿晶体管,首颗 3D 芯片诞生
能够有如此大的提升,也是得益于台积电的 3D WoW 硅晶圆堆叠技术,从而实现了性能和能耗比的全面提升。
正如刚刚所提到的,与 Graphcore 的上一代相比,Bow IPU 可以训练关键的神经网络,速度约为 40%,同时,效率也提升了 16%。
同时,在台积电技术加持下,Bow IPU 单个封装中的晶体管数量也达到了前所未有的新高度,拥有超过 600 亿个晶体管。
官方介绍称,Bow IPU 的变化是这颗芯片采用 3D 封装,晶体管的规模有所增加,算力和吞吐量均得到提升,Bow 每秒可以执行 350 万亿 flop 的混合精度 AI 运算,是上代的 1.4 倍,吞吐量从 47.5TB 提高到了 65TB。
Knowles 将其称为当今世界上性能最高的 AI 处理器,确实当之无愧。

Bow IPU 的诞生证明了芯片性能的提升并不一定要提升工艺,也可以升级封装技术,向先进封装转移。
Graphcore 首席技术官和联合创始人 Simon Knowles 表示,「我们正在进入一个先进封装的时代。在这个时代,多个硅芯片将被封装在一起,以弥补在不断放缓的摩尔定律 (Moore’s Law) 道路上取得的不断进步所带来的性能优势。」
台积电真 WoW!
2018 年 4 月,在美国加州圣克拉拉举行了第二十四届年度技术研讨会。在这次会上,全球最大的半导体代工企业台积电首次对外公布了名叫 SoIC(System on Integrated Chips)的芯片 3D 封装技术。
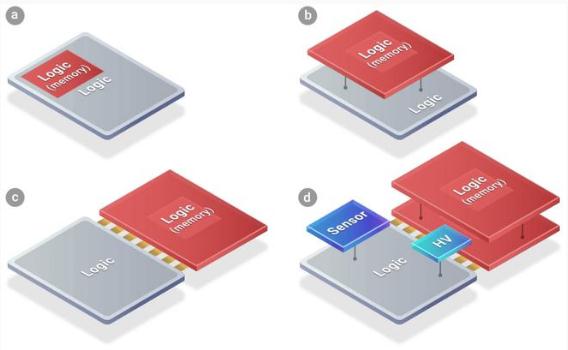
这是一种整合芯片的封装技术,由台积电和谷歌等公司共同测试开发。而谷歌也将成为台积电 3D 封装芯片的第一批客户。
什么是封装技术呢?
封装技术的主要功能是完成电源分配、信号分配、散热和保护等任务。而随着芯片技术的不断发展,推动着封装技术也在不断革新。
而 3D 封装技术,简单来说,就是指在不改变封装体尺寸的前提下,在同一个封装体内,在垂直方向上叠放两个或者更多芯片的技术。
相较于传统的封装技术,3D 封装缩小了尺寸、减轻了质量,还能以更快的速度运转。
台积电在年度技术研讨会上表示,SoIC 是一种创新的多芯片堆叠技术,是一种晶圆对晶圆的键合技术。SoIC 的实现,是基于台积电已有的晶圆基底芯片(CoWoS)封装技术和多晶圆堆叠(WoW)封装技术所开发的新一代封装技术。
晶圆基底芯片(CoWoS),全称叫 Chip-on-Wafer-on-Substrate,是一种将芯片、基底都封装在一起的技术。封装在晶圆层级上进行。这项技术隶属于 2.5D 封装技术。
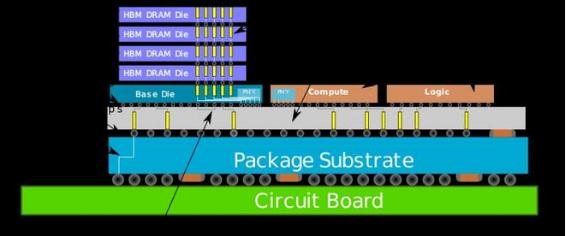
而多晶圆堆叠技术,或者堆叠晶圆(WoW,Wafer on Wafer),简单来说,就是取代此前在晶圆上水平放置工作单元的技术,改为垂直放置两个或以上的工作单元。这种做法可以使得在相同的面积下,有更多的工作单元被放到晶圆之中。
这样做还有另一个好处:每个晶片可以以极高的速度和最小的延迟相互通信。甚至,制造商还可以用多晶圆堆叠的方式将两个 GPU 放在一张卡上。
但也存在问题。晶圆被粘合在一起后,一荣俱荣、一损俱损。哪怕只有一个坏了,另一个没坏,也只能把两个都丢弃掉。因此,晶圆量产或成最大问题。
而为了降低成本,台积电只在具有高成品率的生产节点使用这项技术,比如,台积电的 16nm 工艺。
相较于 CoWoS 和 WoW,SoIC 更倚重 CoW(Chip on Wafer)设计。对于芯片业者来说,采用 CoW 设计的芯片,生产上会更加成熟,良率也可以提升。
值得一提的是,SoIC 能对小于等于 10nm 的制作过程进行晶圆级的键合。键合技术无疑会大大提高台积电在这方面的竞争力。
练手怎么样?
Bow 是 IPU-POD 人工智能计算系统的核心,称为 BOW PODs。
它可以从 16 个 BOW 芯片扩展到 1024 个,提供高达 358.4 千亿次的计算机运算速度,同时配合多达 64 个 CPU 处理器。
新的 Bow-2000 IPU Machine 是 Bow Pod 系统的构建块。
它是基于与第二代 IPU-M2000 machine 同样鲁棒的系统架构,但是配备了四个强大的 Bow IPU 处理器,可提供 1.4 PetaFLOPS 的人工智能计算。
这么厉害的芯片,还不赶快拿来练练手?
近年来,语言模型的参数量不断刷新。从惊艳四座的谷歌 BERT,到 OpenAI 的 GPT-3,再到微软英伟达推出的威震天等等。
都对训练时所需的计算性能提出了更大要求。
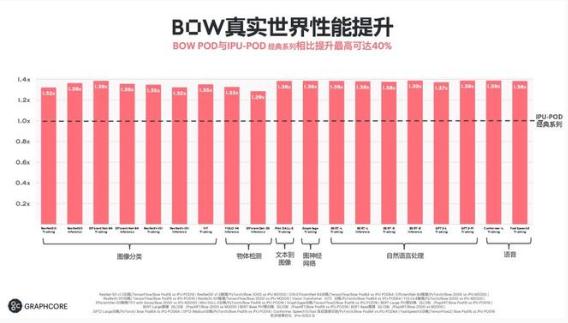
根据 Graphcore 公布的初始数据可以看出,这些模型在最新的硬件形态上都有很大的性能提升。
另外,在图像方面,无论是典型的 CNN 网络,还是近期比较热门的 Vision Transformer 网络,以及深层次的文本到图片的网络。
与上一代产品相比,Bow IPU 都有 30% 到 40% 的性能提升。
对于最先进的计算机视觉模型 EfficientNet,Bow Pod16 能够提供可比 Nvidia DGX A100 系统 5 倍以上的性能,而价格只有它的一半,总体拥有成本优势提升高达 10 倍。
下一步,超级智能 AI 计算机
Graphcore 今天还宣布了一件重大的事,正在开发一款超级智能 AI 计算机,要在 2024 年推出,售价 1.2 亿美元。
我们知道,大脑是一个极其复杂的计算设备,在一个生物神经网络系统中拥有大约 1000 亿个神经元和超过 100 万亿个参数,它提供的计算水平是任何芯片计算机都无法比拟的。
而这款超级智能 AI 计算机 Good 将超越人类大脑的参数能力。
Good 计算机名字何来?是以计算机科学先驱 i.j. Jack Good 的名字命名。
Jack Good 在 1965 年的论文《关于第一台超级智能机器的推测》中就描述了一种超越我们大脑能力的机器。
未来,它可以进行超过 10 Exa-Flops 的人工智能浮点计算,最高可达 4PB 的存储,带宽超过 10PB/秒。
Graphcore 的首席执行官 Graphcore 表示,「当我们创建 Graphcore 的时候,我们脑海中一直有一个想法,那就是建造一台超智能计算机,它将超越人脑的能力,这就是我们现在正在努力做的事情。」
(邯郸网站建设)